#Basics of Neural Networks and Deep Learning - Part 2
Course Overview: Deep Learning Course - Overview
In this course, we will learn about the MNIST dataset, and why good data is so important for training neural networks.
#Content of this block
The marked article is the current one.
- Our Brain and the Perceptron
- MNIST, and why good data is so important
- Structure of a Neural Network
- A Neural Network is learning
- Backpropagation
#What exactly do we need the Data for?
In the last article there was a little description on how a NN is trained. Let's make this description a little bit more detailed:
When we want to train a NN, we need a bunch of data. This Data is then separated in data used for training the NN (~ 75%), and data used for evaluating the NN (~ 25%).
One time through all training data = "epoch"
We need this to make sure, the NN did not "memorize" the training data, i.e. it adjusted the threshold values to solve the exact problem it was given, but nothing more. Such a NN could have an accuracy of probably nearly 100% on the data it was trained with, but it will fail recognizing anything that was not part of the Training Data. That's usually (=always) not what we want.
Maybe think about why we don't want a NN that is specialized on the data it's trained on for a moment...
...
...
Well, if we would want to assign every data-point to some label, you would just take the most basic algorithm, some switch case, or a bunch of if elses, but the use of Neural Networks is to recognize new data correctly. "Never use AI if you don't have to" (a standard program is usually quicker to write, takes no time and money for training, is not as complex as a NN, and you have no room for errors)
This would by the way be an extreme example for overfitting, i.e. the NN getting used to the data it is trained with, but it won't get better on unknown data. (That's also why more training is not equal to better accuracy)
In this picture, we can see three datasets. Let's say, the red points are images of dogs, while the green one are cats. (for the light mode ppl cyan and pink).
These points are our training data.
The line is where our NN is separating the images.In the left image, we can see the result of a NN, that was probably not trained enough (or has not enough layers etc.).
=> UnderfittingIn the middle one, there is an overfitted NN, the NN was probably trained too much. Because of this, the "function" it developed to separate dogs and cats suits the data it was trained for, but it is much too specialized to fit any other data.
The image on the right side shows a balanced NN. This NN was trained exactly right, it's not extremely specialized, but also not just a straight line through the data: It kinda "sees" the "big image", i.e. it will hopefully perform wonderful on new data.
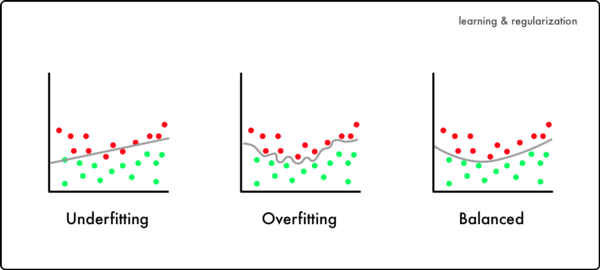
Because of this we check the results with the evaluation data, and make sure the NN will work for data it has never seen before, i.e. is not overfitted.
#Why is good Data so important?
"garbage in, garbage out" - ancient chinese proverb 1
The Data a NN is trained with is (one of) the most important factor(s). You can use wonderful algorithms, but without the right data, your NN cannot be trained properly.
It is sometimes difficult to find a good dataset, and it takes even more time (much more) creating your own data, but a good dataset is the first step towards a good NN.
#What exactly is bad Data?
When you want to develop a NN which will recognize whether the animal in a picture is a dog or a wolve, but all your training pictures of wolves are taken in the mountains (i.e. probably with snow in the background), then the NN will propably classify a dog playing in the snow as a Wolve.
Let's imagine this with a little kid learning. We would say: look, this and this and this are wolves, and the other ones are dogs, and the kid will think "If there is snow, it's a wolve, and without snow, it has to be a dog, easy".
It's the same for NN. If we label images with snow and something dog-alike as wolve, and all other images as dogs, the NN will learn to classify images based on the amount of snow.
Because of this we will need a lot data, and data for every possible situation, to represent the reality. (because in reality, there are also dogs and not only wolves in the snow.)
If you'd be sure, that absolutely all wolves will have snow in the background, while no dog will ever be seen together with snow, it would be absolutely fine to let the NN decide based on snow.
This is by the way why you should always try to understand your data.
Little story:
A group of students once tried autonomous driving, and recorded hundreds of hours of driving. The AI trained with this data drove quite good, but after a while the car reached a bridge, where the car suddenly stopped.
As the students found out later, in all their training data, there was grass on the side of the road, and so the AI did not know what to do when suddenly the grass disappeared at the bidge.
This may be a small issue when recognizing dogs and wolves (depending on the application), but let's imagine a scenario where your code is actually important. In the best case, you're left alone with some pissed customers, but you could also be responsible for much worse (self-driving cars crashing into each other, etc.).
Anyway, we should always try to use good data, as our goal is to optimize our NN, and this starts with using good data for the training.
That problem is one specific kind of biases. A NN with a bias basically means that the content of your data is represented in the responds the NN gives, e.g. the NN copies certain beliefs that are represented in the data.
There are many forms of biases. They can be introduced by incomplete data (e.g. you ignore for example one group of users), wrong data (some of your data entries are wrong) or your data is not representing the reality (dogs are playing in the snow too), etc.
Example:
You get your data by calling people, and asking them questions, for a product where you're not calling people. The data you trained the NN is incomplete, because all the people, that hang up quick are not represented in the data. However, as the final product is used by many people - also people that would hang up the phone - the NN will generate wrong responses for them.
Something that - as i heard - actually happened: An AI was used in court, to predict whether a suspect is innocent or not. As the data it was trained on was incomplete/ not balanced, the AI started to favor quys that were white :/.
TL;DR: When your data is racist, your NN will be too.
Some advice when searching for good data:
- Select training data that's appropriately representative and large enough for your application.
- Test and validate to ensure the results of your NN don't reflect bias due to algorithms or the dataset.
- Understand the training data used, as the dataset could contain labels that can introduce bias.
#Where can we get good Data?
It's quite hard getting good data, because many good/complete/normalized datasets are not available for free. Also they may be not 100% suitable for your project, and so you maybe have to "clean" the data first.
Here's a link with a few datasets for you in case you want to start your own project:
For our first project we are gonna use a free dataset, the MNIST dataset.
#MNIST
The MNIST dataset is a big collection of handwritten numbers (0 - 9). They are all only 28 x 28 pixel small, i.e. increased training speed, and you don't need a graphic card for the training.

This is a quite good dataset, the labels are good, the numbers are written by children and adults, they are already separated into training and evaluation data, there is enough data (60.000 images) and so on... The perfect dataset.
Additionally it's quite easy to load the data, so we won't need much code for this.
The MNIST dataset is kinda the "Hello World" example for Deep Learning.
#The End
Another article finished. In the next two articles we are going to focus more on neural networks (structure and learning process), so we can start developing right after the last article (backpropagation), i.e. in the next block on computer vision.
Next Article: Neural Network Structure
#Footnotes
-
Stole this idea from mikhail berkov's book on NextJS. ↩